
멀티모달 AI의 기술적 이해와 월드모델 | 매거진에 참여하세요
멀티모달 AI의 기술적 이해와 월드모델
#멀티모달 #정의 #현재 #다음단계 #미래 #이해 #기술 #설계 #임베딩 #토큰화




모달리티는 ‘데이터 형식’이 아니라 ‘정보 표현 체계’다
텍스트, 이미지, 음성은 단순히 형식이 다를 뿐이 아니다.
이들은 정보를 인코딩하는 방식 자체가 다르다.
- 텍스트 → 이산적(discrete) 토큰 시퀀스
- 이미지 → 연속적(continuous) 공간 신호 (2D spatial grid)
- 음성 → 시간 기반 연속 신호 (1D temporal wave)
- 영상 → 시간 + 공간 결합 신호 (3D spatio-temporal tensor)
즉, 문제의 본질은 이거다:
서로 다른 통계 구조를 가진 신호를 하나의 계산 구조 안에서 다루는 것
멀티모달의 핵심 난제는 “합치는 것”이 아니라 이질적 통계 구조를 정렬하는 것이다.
공통 임베딩 공간은 왜 가능한가
모든 현대 멀티모달 시스템의 기초는 Representation Learning이다.
각 모달은 고유한 인코더를 가진다:
- Text Encoder (Transformer 기반)
- Vision Encoder (ViT, CNN, Patch-based Transformer)
- Audio Encoder (Spectrogram + Transformer)
이 인코더의 목표는 단 하나다.
고차원 신호를 의미 중심의 벡터 표현으로 압축하는 것
그리고 이 벡터들을 같은 벡터 공간에 배치한다. 이때 핵심 개념이 바로: Joint Embedding Space
수학적으로 보면 각 모달 인코더는 함수다.
- f_text(x_text) → ℝ^d
- f_image(x_image) → ℝ^d
- f_audio(x_audio) → ℝ^d
출력 차원 d를 동일하게 맞춘다.
그 다음 학습 목표는:
의미적으로 같은 샘플 쌍은 벡터 거리를 가깝게, 다른 샘플은 멀어지게.
이를 위해 Contrastive Learning이 주로 사용된다.
이 과정을 통해 모달 간 의미 정렬이 일어난다.
Cross-Modal Alignment의 수학적 직관
이 구조가 안정화되면 이런 현상이 발생한다:
- 텍스트로 이미지 검색 가능
- 이미지로 텍스트 생성 가능
- 공통 의미 기반 추론 가능
즉, 모달은 달라도 의미 표현은 공유된다.
이게 멀티모달의 1차 진화다.
Early / Late / Hybrid Fusion을 더 기술적으로 보자
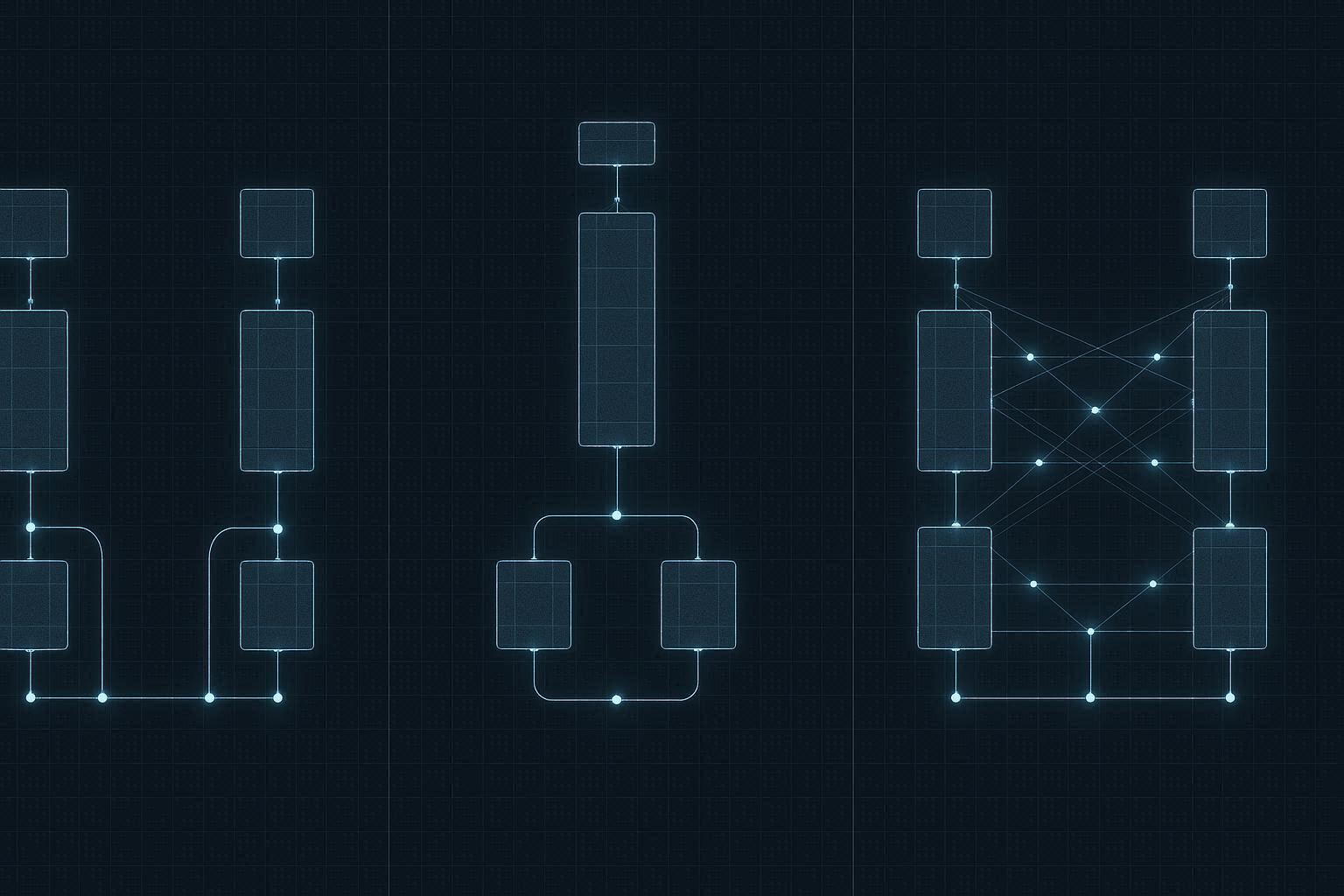
1. Late Fusion : 독립 표현 + 후결합
구조:
각 모달 → 독립 인코딩 → 고수준 표현 벡터 생성 → Fully connected layer에서 결합
문제:
모달 간 저수준 상호작용이 없다 고차원 의미 통합이 제한적이다
이 구조는 “결과 통합”이지 “표현 통합”이 아니다.
2. Early Fusion : 입력 수준 통합
모든 입력을 하나의 시퀀스로 변환한다.
예:
- 이미지 → 패치 토큰화
- 텍스트 → 토큰화
- 오디오 → 프레임 토큰화
그리고 하나의 Transformer에 넣는다.
이 경우:
모달 간 모든 위치에서 상호작용 가능
계산 복잡도 O(n²) 급증
Early Fusion은 강력하지만 비용이 크다.
3. Hybrid Fusion : 현재 주류 구조
현재 대부분의 고성능 모델은 완전 Early도, 완전 Late도 아니다.
구조는 보통 다음과 같다:
- 각 모달은 초기에 독립 인코딩
- 중간 레이어에서 Cross-Attention 삽입
- 최종 단계에서 통합 Transformer
Cross-Attention의 핵심은:
Q는 텍스트에서, K/V는 이미지에서 가져오는 구조.
이 말은:
텍스트 토큰이 이미지 정보를 참조해 의미를 재구성한다는 것
이때부터 “교차 추론”이 가능해진다.
토큰화(Tokenization)의 문제
멀티모달에서 가장 중요한 기술적 이슈 중 하나는 모든 것을 토큰으로 만드는 과정이다.
텍스트는 원래 토큰 기반이다.
하지만:
- 이미지는 패치 단위로 잘라야 하고
- 영상은 시간 단위 프레임으로 나눠야 하며
- 음성은 스펙트로그램으로 변환해야 한다.
이 과정에서:
- 정보 손실 발생
- 해상도 문제 발생
- 계산량 급증
멀티모달 확장의 병목은 사실 토큰화와 시퀀스 길이 문제다.
멀티모달의 진짜 기술적 난제
1. 시퀀스 길이 폭발
- 텍스트 1,000 토큰
- 이미지 패치 576개
- 영상 프레임 수천 개
Transformer은 모달이 늘어날수록 계산 비용은 기하급수적으로 증가한다.
2. 시간적 일관성 유지
영상은 단순 이미지 집합이 아니다.
시간 축을 따라 의미가 변한다.
문제는:
현재 모델은 장기 시간 인과 추론에 약하다.
짧은 클립 요약은 가능하지만 복잡한 상황 전개 이해는 아직 제한적이다.
3. 의미 정렬의 불완전성
“강아지”라는 단어와 강아지 이미지는 대체로 정렬된다.
하지만 추상 개념은?
자유 , 책임 , 의도 , 위협
추상 개념의 모달 간 정렬은 여전히 불완전하다.
World Model : 멀티모달의 다음 단계
지금의 멀티모달 모델은 기본적으로 이렇게 동작한다:
입력 → 표현 정렬 → Attention 기반 통합 → 출력
문제는 이것이 반응형 시스템이라는 점이다.
즉, 입력이 있어야 계산이 시작된다. 모델 내부에 “세계의 구조”가 명시적으로 존재하지는 않는다.
1. World Model이란 무엇인가
World Model은 단순한 표현 정렬이 아니다.
세계의 상태(state)와 상태 전이(dynamics)를 내부적으로 모델링하는 구조
형식적으로는: 현재 상태 + 행동 aₜ → 다음 상태 sₜ₊₁ 을 예측하는 모델이다.
이 개념은 원래 강화학습(RL)에서 출발했지만, 멀티모달과 결합하면서 의미가 확장된다.
2. 왜 멀티모달에서 World Model이 중요한가
현재 멀티모달은:
- 정적 장면 설명은 잘한다
- 짧은 시간 패턴은 이해한다
하지만
- 장기 상황 전개
- 인과적 구조
- 물리적 제약 이해
는 약하다.
World Model은 단순한 “패턴 매칭”을 넘어서
시간을 따라 세계가 어떻게 변하는지를 학습한다.
Unified Token Architecture

1. 모든 것을 토큰으로
현재 대부분의 멀티모달 모델은 모달마다 다른 인코더를 쓴다.
Unified Token Architecture는 다르게 접근한다.
모든 입력을 동일한 토큰 형식으로 변환하고 단일 Transformer로 처리한다.
- 텍스트 토큰
- 이미지 패치 토큰
- 오디오 프레임 토큰
- 영상 스페이스-타임 토큰
모두 같은 형식의 “token”으로 취급한다.
2. 장점
구조 단순화
확장성 증가
모달 추가 용이
즉,
새로운 감각이 추가되어도
같은 계산 구조 안에 넣을 수 있다.
3. 기술적 난제
하지만 문제가 있다.
① 토큰 폭발
영상은 수천 개의 토큰을 만든다. 스케일링이 어렵다.
② 정보 밀도 차이
텍스트 토큰 하나와 이미지 패치 하나는 정보량이 다르다.
같은 토큰으로 취급하는 것이 항상 최적은 아니다.
③ 동적 해상도 문제
영상·이미지는 공간/시간 해상도 선택이 중요하다.
모든 것을 균일 토큰으로 만들면 정보 손실과 계산 부담 사이에서 타협이 필요하다.
결론 : 구조적 진화의 현재 위치
멀티모달 AI는 단순히 “입력이 늘어난 AI”가 아니다.
정확히 말하면:
이질적 신호를 공통 표현 공간으로 압축하고,
Attention 메커니즘을 통해 상호 참조하도록 만든 계산 구조다.
현재 멀티모달 AI는
1. 표현 정렬은 안정화되었고
2. 교차 Attention 기반 추론은 가능하며
3. 생성 모델과 통합되었다
그러나
1. 물리적 세계 모델은 아직 불완전하며
2. 장기 인과 추론은 제한적이고
3. 계산 비용은 여전히 가장 큰 병목이다

- link_kakaolink_kakao_url
- link_operatorlink_operator_url
- link_investhelp@letspl.me
- link_ad_urllink_ad
